Deep Reinforcement Learning Note 1 - Playing Pong with Policy Gradient
This is my first post in this year and also my first post about machine learning. Formerly, I think I am gonna make this blog only for low-level and security playground only –that’s why the name is postmortem. But, as you know life is dynamic! That’s makes it interesting 😃
Prelude
It’s been over a year since AlphaGo wins its match versus Lee Sedol with great victory. And not so long ago, AlphaGo Zero –self taught version of AlphaGo– has been published. One of the core component of AlphaGo is DQN –deep Q-network which had successfully completed a diverse of classic Atari games.

Lee Sedol during the match
Following the success of DQN, deep reinforcement learning (RL) at general has gained much popularity. The recent breakthroughs from OpenAI been released (like this and this), has proved further capabilities of deep RL. In this post, I’m going to tell my story about building a simple deep RL agent to play Atari Pong.
Lets Start with Some Theory
Before we dive into RL, I suggest you to understand about machine learning in general and a bit about Python and linear algebra. If you need resources about it, here are bunch of interesting resources to learn ML:
- Machine Learning is Fun!
- Learning to See by Welch Lab
- Machine learning course videos by Andrew Ng. You could also enroll in his course on Coursera
- Neural Networks Demystified by Welch Lab
- Neural net course videos by Geoffrey Hinton (Coursera mirror)
Reinforcement learning is an exciting area of machine learning. It can be classified somewhat between supervised and unsupervised learning. Because basically it is the learning method to make an efficient strategy in a given environment.
There are few core component of reinforment learning: environment state, action, observation state, policy, and reward. Agent will make action for every timestep. Every action from the agent will affect the environment. And then environment will make feedback with reward and change of environment state. Depend on the problems, environment state will be observed by agent to make update to internal state of agent –called observation state. Set of action performed as a function of state is called policy. Policy can depend on observation state or not (can be deterministic, randomized or fixed).

RL loopback
Main goal of RL is to determine the best policy in order to maximize the expected rewards. We can imagine a policy as a path need to be taken to reach the goal. The longer the path taken, the least score can be obtained. If we for example, take the “dangerous” path which contains trap, we get the penalty and reducing the final score too. To achieve the best policy, sometimes we need to leave the most promising policy to explore another uncertain policy. This problem known as exploration vs exploitation dilemma.
Using value function, we could determine whether our policy is good enough or need to be improved. Basically, there are 2 main method for policy improvement, by using policy update and value update. Value based method perform update by choosing maximum value available for each state. Maximum value computed by taking all possible action and take the most promising ones. Value based method does not care about certain policy during learning phase. On the other hand, policy based certainly does care about policy. This method changing policy step by step until value obtained maximized. In short, value based is good for minimal state space, and policy based is good for minimal actions. For further explanation, I suggest you to read my references on the bottom of this page. My post here will focus only on my experiment about Atari Pong games.
Get to the Observation

Pong table
Now, we are going to decide which method will we use. There are some concerns about that. First of all, our pong table is an example of continous environment. Even though our monitor screen is finite, of course we cannot enumerate all possible states of pong table condition. Hence, we still prefer using simpler method using policy based approach called policy gradient.
In plain English, policy gradient is a method to compute rate of reward change over a policy applied at current state. Probabilities for each action will increase based on cumulative reward reached. Higher reward gotten, higher chance the action will be performed. I am going to use gym package from OpenAI. They provide numerous environment samples for machine learning training and testing. And the best part of it is they are given in discrete inputs.
Next, we need to design our DNN structure. For the input, we are given a 210x160x3 byte array represent a window frame. We would like to preprocessing this frame to make it easier for our NN doing learning. This can be done by crop the outside border and convert all pixel to binary color (black and white). There are 6 available action in the environment given, so thats our output layer should look like. We will use 1 hidden layer with 800 neuron and mapping those to 6 output layer.
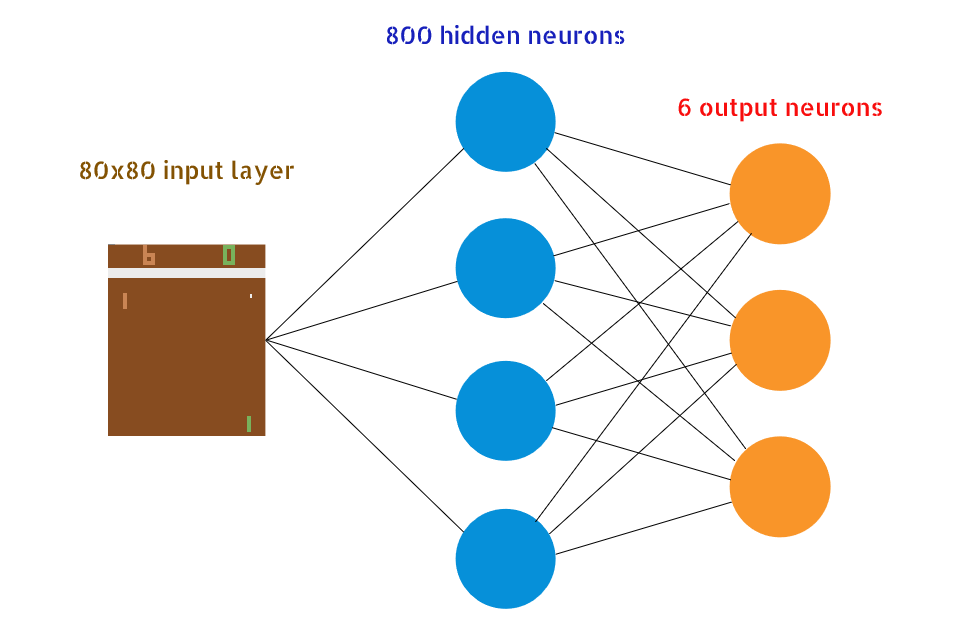
Then, we will connect our DNN to policy gradient to compose a deep RL network. We will define a cost function using average rewards of the last 100 episodes. Updating performed for each batch of 8 episodes. Each episode consist of multiple games of arbitrary number. Whenever one of the players score 21 first, episode will end. Total score computed from sum of score we got from each games. If we fail to return the ball, supply -1. Otherwise, we get 1.
Weights updating will be performed by applying gradient descent with the batch score as multiplier. In other words, probability of a policy trajectory will be updated based on score. Greater the score obtained, probabilities will be increased. After thousands plays, the optimal trajectory will get the biggest score –thus, biggest probability.
Remarks
We should be ready to the training now! Now, install numpy and gym. And then, you can copy from my implementation here or Karpathy’s (with different neural anatomy). What you should do is just make some coffee and wait about a day. Your model should be ready to test then.
After training has completed, you can run the script with turning on param resume and render to view the gameplay. You can notice that your agent has smart enough to beat the hardcoded AI. It also can perform and even return a smash. Pretty interesting. Maybe I will make the mobile version from this model. But for now, I think my FYP comes first 😺, perhaps
References
- Reinforcement Learning: An Introduction by Sutton
- CS213n Convolutional Neural Net for Visual Recognition course slide about RL
- Deep Reinforcement Learning Demysitifed (Episode 2) — Policy Iteration, Value Iteration and Q-learning
- Pong with Reinforcement Learning Tutorial
- Simple RL Series with Tensorflow
- Lecture slide from David Silver
- Summary and additional resources about policy gradient method